1. 기본 개념
① 정의
• 분류 작업
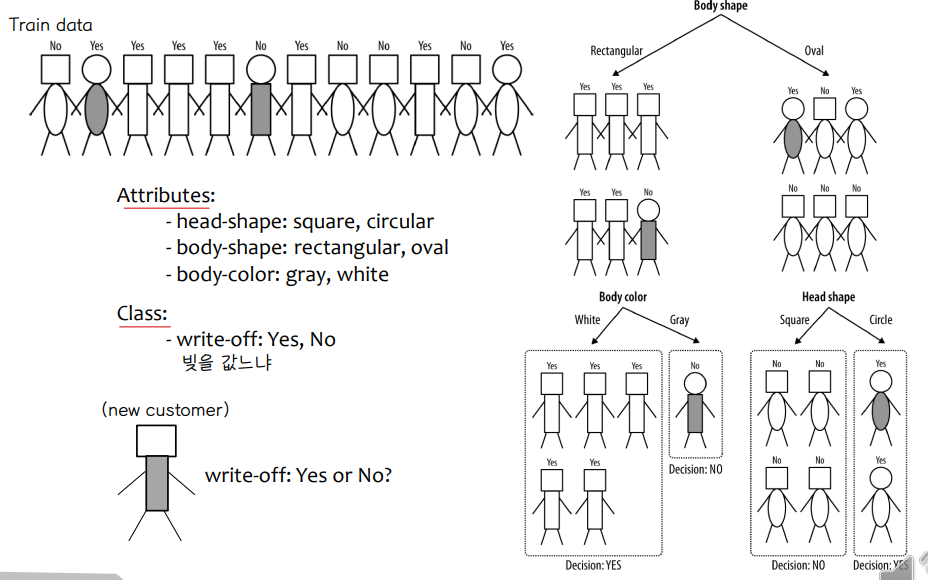
• 레코드 모음이 주어짐 (훈련 세트), 우리는 모델을 찾습니다 클래스 속성 다른 속성 값의 함수로. 각 레코드에는 속성 집합이 포함되며 속성 중 하나는 수업.


• 이전에 보이지 않는 레코드(테스트 세트) 가능한 한 정확하게 수업을 배정받아야 합니다.
아 테스트 세트 결정하는 데 사용됩니다. 정확성 모델의. 일반적으로 주어진 데이터 세트는 훈련 세트와 테스트 세트로 나뉘며 훈련 세트는 모델을 구축하는 데 사용되고 유효성 검사에 사용되는 테스트 세트
② 예시
• 종양 세포를 양성 또는 악성(양성 종양)으로 예측
• 신용카드 거래를 적법 또는 사기로 분류(사기거래탐지)
• 단백질의 2차 구조를 알파-나선, 베타-시트 또는 랜덤 코일로 분류
• 뉴스 기사를 금융, 날씨, 연예, 스포츠 등으로 분류
③ 기술

2. 의사결정나무 유도
① 예시
• 모든 리프 노드는 하나의 동일한 레이블을 가집니다.
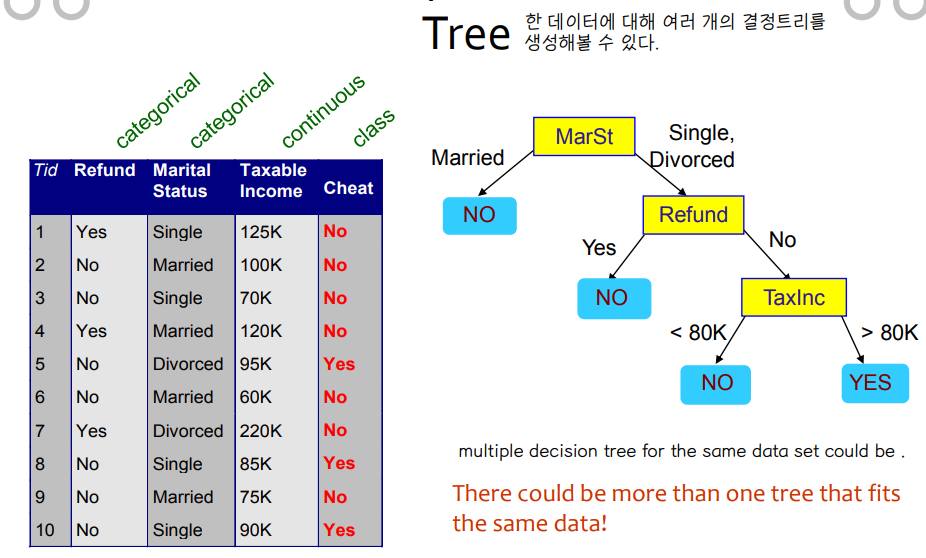
• 동일한 데이터에 맞는 트리가 둘 이상 있을 수 있습니다.
② 의사결정나무 분류
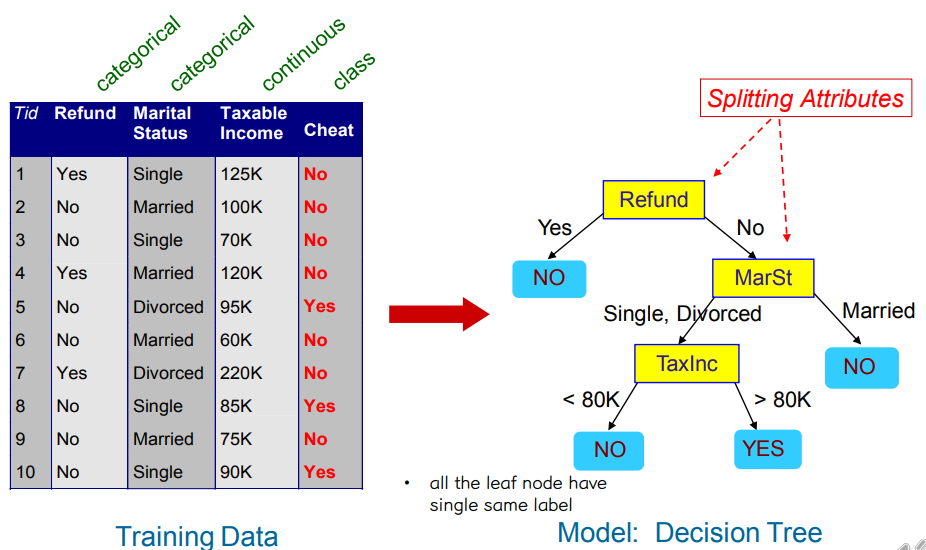
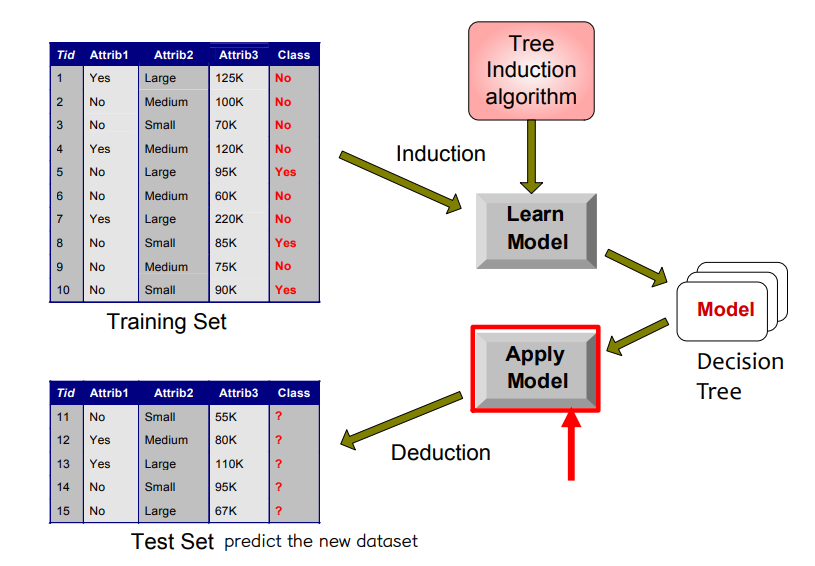
• 학습, 테스트 데이터 세트
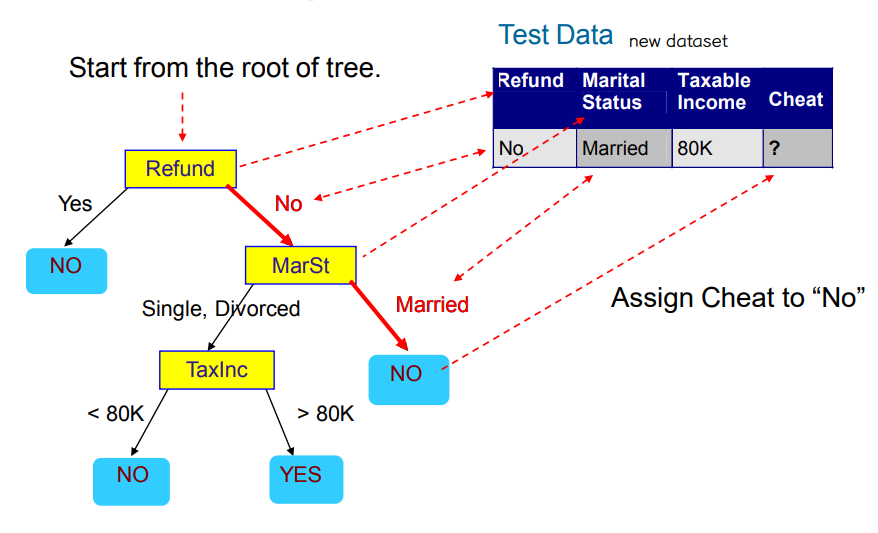
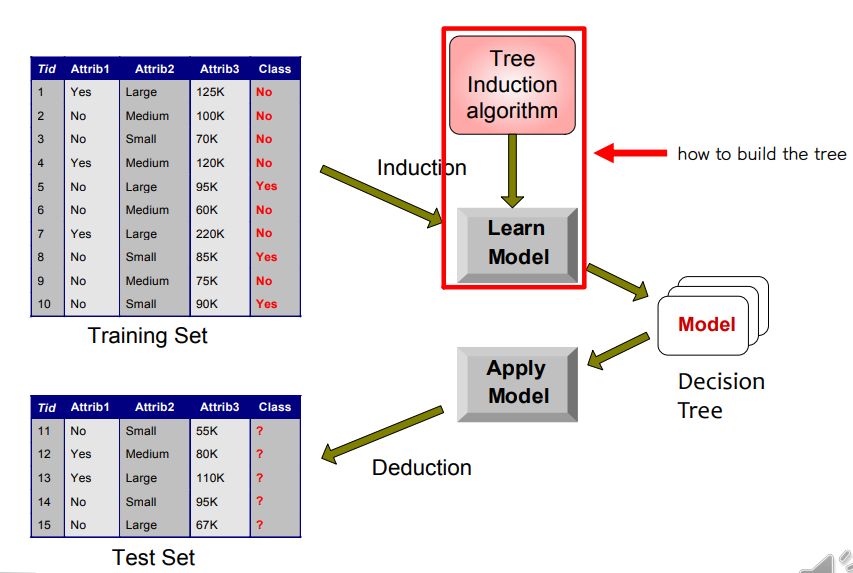
• 트리 유도: 욕심쟁이 전략
특정 기준(지니 지수, 이득 비율…)을 최적화하는 속성 테스트를 기반으로 레코드 분할
데이터 분할 방법
(1) 속성에 조건을 지정하는 방법(테스트 조건을 설정하는 방법)
(2) 최적의 스플릿을 결정하는 방법과 스플릿을 중지할 시기
③ 테스트 조건 지정 방법
• 테스트 조건 지정 방법
(1) 의지하다 속성 유형 : 명목, 서수, 연속
(2) 의존 분할 방법의 수 : 양방향 분할, 다중 분할
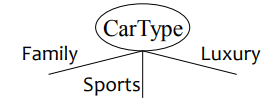
ㅏ. 기준으로 분할 명사 같은 속성
다자간 분할 : 사용 파티션 수만큼 별개의 값
이진 분할: 값을 다음으로 나누기 두 개의 하위 집합최적의 파티셔닝을 찾아야 합니다.
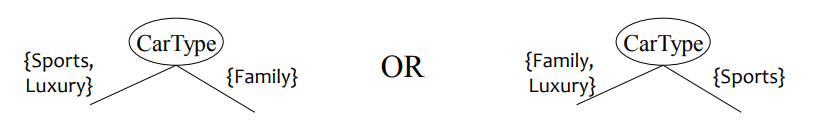
비. 기준으로 분할 서수 속성
다자간 분할 : 사용 파티션 수만큼 별개의 값
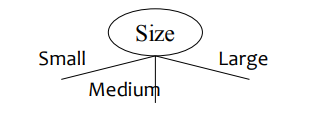
바이너리 split: 값을 다음으로 나눕니다. 두 개의 하위 집합; 최적의 파티셔닝을 찾아야 합니다.
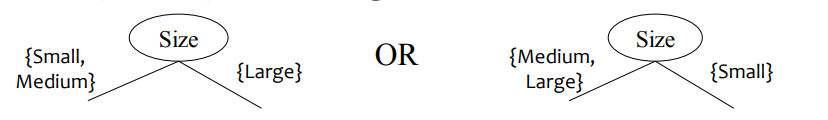
서수 속성에 대해 이진 분할을 수행할 때 다음과 같이 분할하는 것은 적절하지 않습니다. 이는 {Small, Large}가 연속된 값이 아니기 때문입니다. 각 분기의 자식 노드는 의미 있는 조합이어야 합니다.

씨. 기준으로 분할 마디 없는 속성
이분법 분할의 경우 가장 좋은 분류를 할 수 있는 최적의 절단점을 찾는 것이 중요하고, 다원 분할의 경우 이산화(discretization, binning)가 잘 이루어져야 한다.

④ 최상의 분할을 결정하는 방법
• 최상의 스플릿을 결정하는 방법
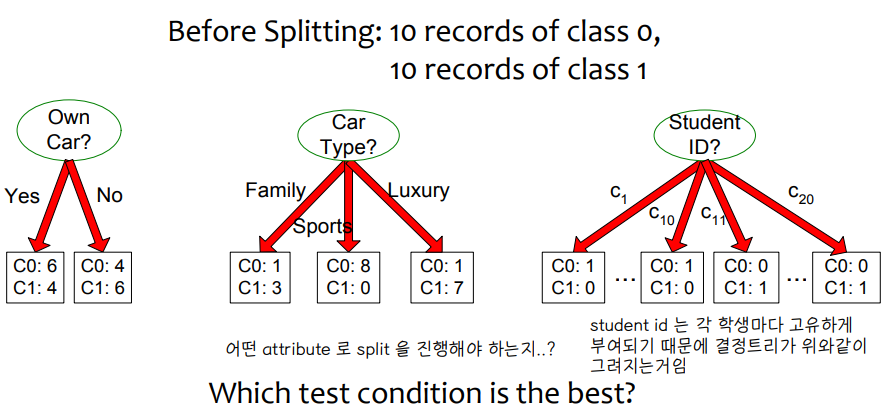
어떤 테스트 조건이 가장 좋은가요?
욕심쟁이 접근법을 사용할 때, 동종의 클래스 분포가 있는 노드를 기반으로 트리를 형성하는 것이 좋습니다.

비균질 = 높은 불순물의 정도
균질 = 낮은 불순물의 정도
• 예
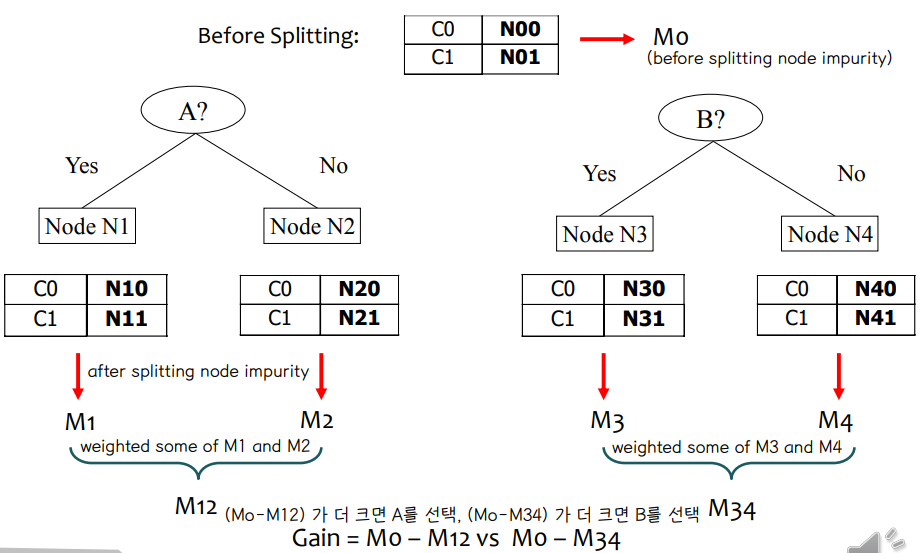
M0 : 분할 전 노드 불순물, M12 : A 변수를 기준으로 분할 후 노드 불순물, M34 : B 변수를 기준으로 분할 후 노드 불순물
얻다 = M0 – M12 vs M0 – M34 ⇨ (M0-M12)가 크면 A, (M0-M34)가 크면 B 선택
3. 지니지수(카트)
① 불순물 측정치 : GINI
• 주어진 노드 t에서 지니 계수 찾기
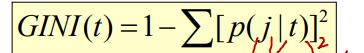
⇨ P(j | t) = 노드 t에서 클래스 j의 상대 빈도
⇨ 지니 계수 값이 작을수록 좋습니다.
⇨ 최대 지니계수 = 1 – 1/nc , nc = 레코드 수: 모든 레코드가 모든 클래스에 균등하게 배포되는 경우. 이때 흥미로운 정보는 최소 상태입니다(사용 가능한 정보가 없는 최악의 경우). P(j | t) = 1/nc임을 알 수 있습니다.
⇨ 최소 지니계수 = 0.0 : 이는 모든 레코드가 하나의 클래스에만 할당됨을 의미합니다. 이때 흥미로운 정보는 최대 상태(얻어야 할 정보가 많은 경우)
• 예

• 지니계수 기준 나뉘다 어떻게
사용 카트 (분류 및 회귀 트리)SLIQ, 스프린트
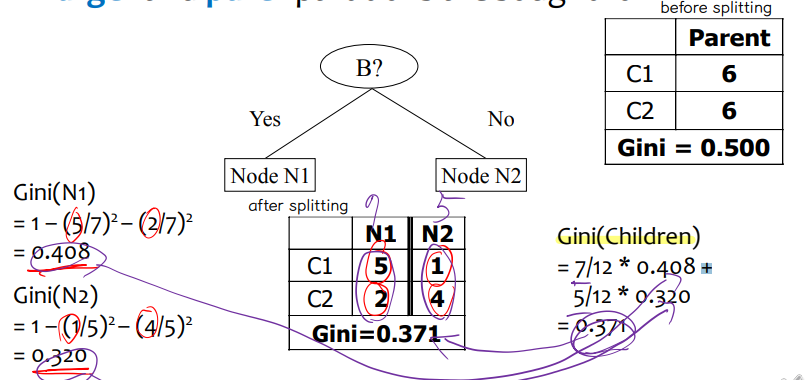
노드 p를 k개의 파티션(자식)으로 분할할 때 분할의 품질을 측정하는 방법은 다음과 같습니다.

하위 i의 레코드 수 ~에노드 p의 레코드 수 N 각 자식 노드에 대한 지니 계수를 계산하고 가중 합계를 수행합니다.
② 속성
• 바이너리
두 개의 파티션으로 분류
크게 그리고 더 순수한 파티션을 추구합니다
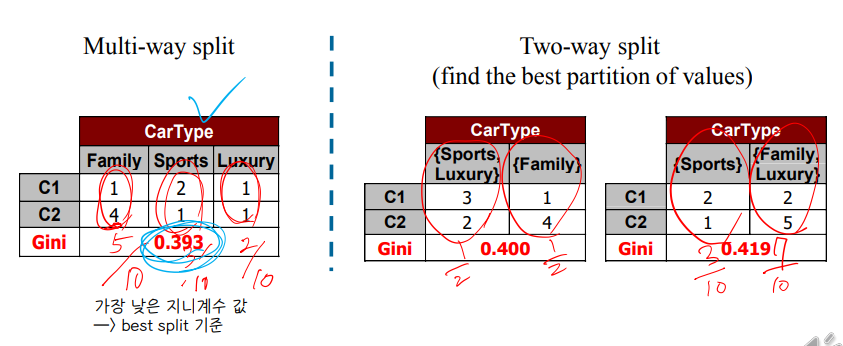
• 범주형
각 고유 값에 대해 우리는 각 클래스의 카운트를 수집 데이터 세트에서 카운트 매트릭스 사용 결정을 내리다
• 마디 없는
에 대한 몇 가지 선택 분할 값 v

가능한 분할 값의 수 = 고유 값의 수

최상의 v를 선택하는 방법: 각 v 값에 대해 데이터베이스를 스캔합니다. 카운트 행렬을 설계하고 지니계수를 계산한다 → 그러나 일일이 계산하는 것은 계산상 비효율적이다.
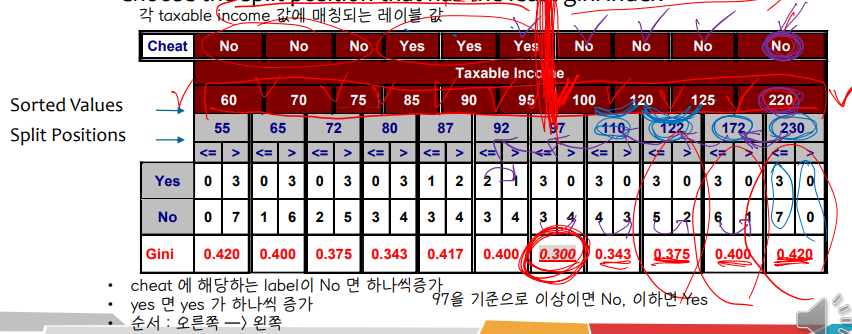
효율적인 계산 방법: 각 속성에 대해 값을 정렬하고 이 값을 선형 스캔하고 매번 카운트 매트릭스와 지니 계수를 업데이트합니다. 지니 계수 값이 가장 작은 위치를 기준으로 분할합니다.
예를 들어, 첫 번째 데이터 프레임에서 과세 소득 변수는 연속 변수에 해당하므로 위의 방법과 같이 최상의 분할 위치를 찾을 수 있습니다. 과세 소득 변수의 값이 정렬되면 각 값의 중간 값이 분할 위치로 간주됩니다. 분할을 해당 중앙값 위 또는 아래로 설정한 후 각 분할 위치를 기준으로 지니계수를 계산합니다. 치트 변수의 레이블을 기준으로 예 또는 아니오로 할당된 횟수를 쉽게 계산할 수 있습니다. (직접 해보십시오)
③ 지니지수의 단점
• 지니계수의 한계
ㅏ. 동일한 크기의 하위 집합에 대한 편향
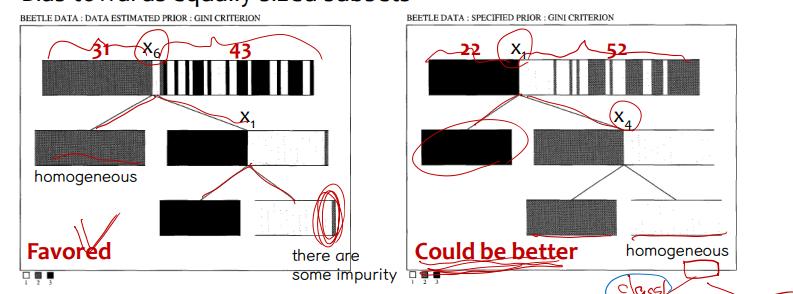
• 탐욕적으로 운영되기 때문에 나중에 효율을 고려하지 않고 해당 단계에서 최선을 선택한다. 따라서 위의 그림에서는 x6이 좀 더 균형 있게 분할되어 최종적으로 왼쪽 분류가 선택됩니다. 그러나 후속 분류에서 x1이 보다 균일하게(균형 있게) 분할되기 때문에 최종 불순물 결과는 x1에 대해 더 좋습니다.
• 순수한 자손
총 7개의 클래스가 있는 경우 데이터셋을 클래스1과 클래스2로 나눈 경우
– 선택 1 : 최대한 빨리 1급과 2급으로 나누기 ⇨ 우대
– 옵션 2: (클래스1,2)와 다른 클래스로 구분 ⇨ 더 나을 수 있었다: 최종 결과에서는 더 좋았겠지만 클래스 1과 클래스 2의 혼합은 순수하지 않기 때문에 선호하지 않습니다.
④ 알고리즘 카트
1. 각 속성의 최적 분할 찾기: 노드가 분할될 때 지니계수를 낮추는 지점이 최적의 분할 지점입니다.
2. 노드 최고의 분할 찾기: 1단계에서 찾은 최상의 분할 값 중에서 지니 계수가 가장 낮은 값을 선택합니다.
3. 중지 규칙이 만족되지 않을 때까지 2단계를 반복합니다.